백엔드 개발자를 위한 한 번에 끝내는 대용량 데이터 & 트래픽 처리 초격차 패키지 Online.
1. mysql 대용량 트래픽 관리
* 스케일업, 스케일 아웃

* 대용량 트래픽 제어 : 캐시, 로드밸런서, 비동기큐

* 대용량 트래픽 분산관리 기법

[참고 : 캐싱]
[Database] 캐싱과 캐싱 전략에 대해 알아보자
Cache Cache는 데이터나 값을 저장하는 임시 저장소로, 데이터를 더 빠르고 효율적으로 액세스할 수 있게 해준다. 원본 데이터 접근보다 빠르다. 같은 데이터를 반복적으로 접근하는 상황에서 사용
loosie.tistory.com
* 대용량처리 비동기처리 메시지 큐
메시지 큐를 이용한 비동기처리 및 에러 처리 | 개발자 이동욱
메시지 큐를 이용한 비동기 요청 처리 요청을 처리하는 방법에는 전통적인 동기식 방식도 있지만, 비동기식 방식도 있는데, 동기 방식이 클라이언트가 요청을 보내면 처리한 다음에 응답이 오
dongwooklee96.github.io
하기 기술들 유기적 사용

- 데이터 웨어하우스
https://www.sap.com/korea/insights/what-is-a-data-warehouse.html
데이터 웨어하우스란? | 정의, 구성 요소, 아키텍처 | SAP Insights
데이터 웨어하우스(DW)는 다양한 소스로부터 대량의 데이터를 연결해 BI, 리포팅, 분석을 제공하는 디지털 스토리지 시스템입니다.
www.sap.com

- 로그시스템
데이터가 어디에서 발생?
https://zzsza.github.io/data/2021/06/13/data-event-log-definition/
데이터 로그 설계, 데이터 로깅, 이벤트 로그 설계, 데이터 QA의 모든 것
이벤트 데이터 로그 설계, 데이터 로그 설계, 데이터 로깅, 데이터 QA에 대해 작성한 글입니다 키워드: 데이터 로깅, 데이터 로깅이란, 데이터 로깅 시스템, Firebase event logging, 이벤트 로그 설계,
zzsza.github.io
https://server-talk.tistory.com/37
MySQL 로그 파일 관리
MySQL 로그 파일 관리 MySQL 로그 소개 MySQL은 일반적으로 3종류의 로그가 있습니다. 1) 에러로그 - MySQL 구동과 모니터링, 쿼리(Query) 에러에 관련된 메시지를 포함해서 표시됩니다. 2) General 로그 - MySQ
server-talk.tistory.com
[스크랩] Oracle Log 확인
http://talkativelee.tistory.com/61 1) Oracle Log 위치 및 용도 ▶ /oracle/admin/orcl/bdump background process trace files을 저장하며 trace files를 통해서 각 process들의 이상유무 및 장애시 원인분석 ▶ /oracle/admin/orcl/udump
99lib.tistory.com
- 매트릭수집시스템
https://velog.io/@sonar0/Prometheus%EB%A1%9C-Metric-data-%EC%88%98%EC%A7%91%ED%95%98%EA%B8%B0
Prometheus개요와 Metric data 수집하기
Prometheus개요와 Metric data 수집하기
velog.io
- 전문검색 색인

[엘라스틱서치] 실무 가이드(1) - 검색 시스템
검색 엔진(search engine)은 웹에서 정보를 수집해 검색 결과를 제공하는 프로그램이다. 검색엔진은 검색 결과로 제공되는 데이터의 특성에 따라 구현 형태가 각각 달라진다. 검색 시스템(search system
12bme.tistory.com
- 푸시서

https://dataonair.or.kr/db-tech-reference/d-lounge/expert-column/?mod=document&uid=52355
소통을 위한 협업 도구 ‘푸시 서버’
소통을 위한 협업 도구‘푸시 서버’ 사내정보 유출 차단 및 운영비용 절감 효과 스마트폰, 태블릿 등 모바일 기기가 등장하면서 기존 웹사이트를 통해 이용하던 서비스의 알림을 쉽고 편리하
dataonair.or.kr
* 2022년 기준 DB순위

* mysql 서버 구조 : mysql 엔진 -두뇌, 스토리지 엔진 - 저장,분석

* mysql과 오라클 캐시 비교
(mysql 쿼리캐시는 조회성능 높으나 캐시데이터 관리에 더 높은 비용)

Clustered Index & Non-Clustred Index
https://velog.io/@gillog/SQL-Clustered-Index-Non-Clustered-Index
[SQL] Clustered Index & Non-Clustered Index
앞서 Index에 대해서 정리 했었지만, Clustered Index와 Non-Clustered Index를 자세히 다루지 않아 이번 시간에 자세히 두 Index의 차이를 정리해보려 한다.Index는 DB의 테이블에 데이터가 많을 때, 검색 속도
velog.io
Redo - Undo
https://brownbears.tistory.com/181
[DB] 트랜잭션, REDO와 UNDO 개념
트랜잭션이란?데이터베이스 트랜잭션(Database Transaction)은 데이터베이스 관리 시스템 또는 유사한 시스템에서 상호작용의 단위입니다. 여기서 유사한 시스템이란 트랜잭션이 성공과 실패가 분명
brownbears.tistory.com
Buffer Pool
버퍼 풀 (buffer pool)은 메인 메모리 내에서 데이터과 인덱스 데이터가 접근될 때 해당 데이터를 캐시하는 영역이다. 버퍼 풀을 통해서 자주 접근되는 데이터를 메모리에서 바로 획득할 수 있으며 전체 작업의 수행 속도를 증가 시킬 수 있다. MySQL을 위한 서버에서는 물리 메모리의 최대 80%까지를 InnoDB의 버퍼 풀로 할당하여 사용하는 경우가 많다.
https://flashsql.github.io/innodb-doc-kr/blog/innodb/5.1.buffer-pool.html
InnoDB | Buffer Pool
Buffer Pool 버퍼 풀 (buffer pool)은 메인 메모리 내에서 데이터과 인덱스 데이터가 접근될 때 해당 데이터를 캐시하는 영역이다. 버퍼 풀을 통해서 자주 접근되는 데이터를 메모리에서 바로 획득할
flashsql.github.io
데이터 입출력시 유의 :
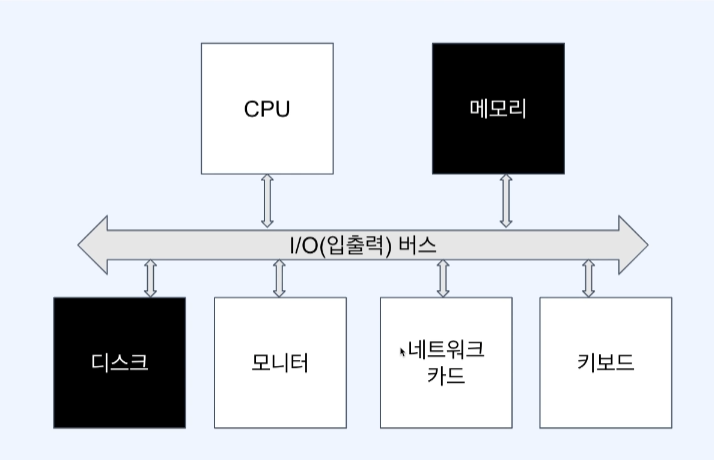

데이터베이스의 성능핵심은 디스크 접근을 최소화하고 메모리에서 처리하도록 해야함(메모리가 빠르므로)

결국 데이터베이스의 성능의 핵심은 디스크의 랜던 I/O(접근)을 최소화 하는
인덱스의 핵심은 탐색(검색) 범위를 최소화 하는 것(Hash Map, List, Binary Search Tree..)




https://ssocoit.tistory.com/217
[자료구조] 간단히 알아보는 B-Tree, B+Tree, B*Tree
위 글을 보고 정리를 하지 않을 수 없었습니다. 가슴이 시키네요;; 그렇다면 바로 B-Tree, B*Tree, B+Tree의 특징에 대해서 알아봅시다. 목차 0. 이진트리 B-Tree, B*Tree, B+Tree에 대해서 알아보자면서 갑자
ssocoit.tistory.com


https://mantaray.tistory.com/38
ORACLE과 MYSQL의 차이점
구조적 차이 오라클 : DB 서버가 통합된 하나의 스토리지를 공유하는 방식 MYSQL : DB 서버마다 독립적인 스토리지를 할당하는 방식 조인 방식의 차이 오라클 : 중첩 루프 조인, 해시 조인, 소트 머
mantaray.tistory.com


하나의 쿼리에는 하나의 index만 탄다
여러 인덱스 테이블을 동시에 탐색하지 않는다.
그래서 where , order by , group by 혼합해서 사용할때는 index를 잘 고려해야한다.
(index는 쓰기를 희생하고 조회를 얻는것으로 테이블을 만드는 비용이다.)
Part2 비즈니스 요구사항에 유여한 MongoDB
MongoDB는 확장성, 유연성 및 성능을 위해 설계된 널리 사용되는 오픈 소스 문서 지향 NoSQL 데이터베이스입니다. MongoDB는 중첩 구조를 가질 수 있고 빠른 쿼리를 위해 인덱싱할 수 있는 유연한 JSON 유사 문서에 데이터를 저장합니다. MongoDB는 높은 확장성, 실시간 분석 및 데이터 기반 의사 결정이 필요한 비즈니스 애플리케이션에 자주 사용됩니다.
몽고DB 아키텍처:
MongoDB는 분산 데이터베이스 시스템이므로 여러 노드에서 수평으로 확장할 수 있습니다. MongoDB는 하나의 노드가 기본 노드로 작동하고 다른 노드는 보조 노드로 작동하는 마스터-슬레이브 복제 모델을 사용합니다. 기본 노드는 모든 쓰기 작업 수신을 담당하고 보조 노드는 데이터를 비동기적으로 복제합니다.
MongoDB는 또한 샤딩을 지원하여 여러 노드에서 데이터를 수평으로 분할할 수 있습니다. 샤딩은 여러 노드에 데이터를 분산하여 성능과 확장성을 향상시키는 데 사용됩니다.
비즈니스 요구 사항을 위한 MongoDB:
MongoDB는 다음을 비롯한 다양한 비즈니스 애플리케이션에 매우 적합합니다.
- 전자상거래: MongoDB를 사용하여 제품 카탈로그, 고객 데이터 및 주문 데이터를 저장하고 관리할 수 있습니다. MongoDB는 대량의 데이터를 처리할 수 있으며 증가하는 비즈니스 요구 사항을 수용하도록 쉽게 확장할 수 있습니다.
- 콘텐츠 관리: MongoDB를 사용하여 웹사이트 및 모바일 애플리케이션의 콘텐츠를 저장하고 관리할 수 있습니다. MongoDB의 유연한 문서 모델을 사용하면 텍스트, 이미지 및 비디오를 비롯한 다양한 유형의 콘텐츠를 쉽게 저장하고 쿼리할 수 있습니다.
- 금융 서비스: MongoDB는 거래 데이터, 계정 데이터 및 시장 데이터와 같은 금융 데이터를 저장하고 분석하는 데 사용할 수 있습니다. MongoDB의 실시간 분석 기능은 금융 서비스의 실시간 의사 결정에 매우 적합합니다.
- 의료: MongoDB는 환자 데이터, 전자 의료 기록 및 의료 영상 데이터를 저장하고 관리하는 데 사용할 수 있습니다. MongoDB의 확장성과 유연성은 대량의 의료 데이터를 처리하는 데 매우 적합합니다.
- 사물 인터넷(IoT): MongoDB는 센서 및 스마트 장치와 같은 IoT 장치의 데이터를 저장하고 분석하는 데 사용할 수 있습니다. MongoDB의 유연성과 확장성은 대량의 IoT 데이터를 처리하고 이 데이터에 대한 실시간 분석을 수행하는 데 매우 적합합니다.
요약하면 MongoDB는 광범위한 비즈니스 애플리케이션에 적합한 강력한 데이터베이스 시스템입니다. 확장성, 유연성 및 성능은 대용량 데이터를 처리하고 실시간 분석을 수행하는 데 이상적인 선택입니다. 비즈니스 애플리케이션에서 MongoDB를 활용하면 시스템의 확장성, 유연성 및 성능을 향상시킬 수 있습니다.

Part3. 고성능 서비스를 위한 Redis활용 및 아키텍처(2009년)

Redis는 데이터베이스, 캐시 및 메시지 브로커로 사용할 수 있는 오픈 소스 메모리 내 데이터 구조 저장소입니다. 값이 문자열, 해시, 목록, 세트 및 정렬된 세트와 같은 다양한 데이터 구조일 수 있는 키-값 저장소입니다. Redis는 고성능, 확장성 및 유연성으로 유명하여 고성능 서비스 구축을 위한 인기 있는 선택입니다.
레디스 아키텍처:
Redis는 단일 스레드 애플리케이션이므로 모든 요청이 단일 스레드에서 처리됩니다. 이 아키텍처를 사용하면 스레드 동기화로 인한 오버헤드가 없으므로 Redis가 매우 효율적이고 성능이 좋습니다. Redis는 들어오는 요청과 응답을 처리하기 위해 이벤트 루프를 사용하는 이벤트 기반 모델을 사용합니다.
Redis는 클러스터링도 지원하므로 수평적 확장이 가능합니다. Redis Cluster는 여러 노드에 데이터를 분산하여 더 큰 데이터 세트와 더 높은 처리량을 허용합니다. Redis 클러스터는 각 마스터 노드에 하나 이상의 복제본 노드가 있는 마스터-슬레이브 아키텍처를 사용합니다. 복제본 노드는 데이터 중복 및 장애 조치에 사용되므로 마스터 노드에 오류가 발생하면 복제본 노드 중 하나가 대신할 수 있습니다.
Redis 사용률:
Redis를 사용하여 고성능 서비스를 구축하는 방법에는 여러 가지가 있습니다. 몇 가지 일반적인 사용 사례는 다음과 같습니다.
- 캐싱: Redis는 자주 액세스하는 데이터를 메모리에 저장하는 캐시로 사용할 수 있으므로 데이터베이스를 쿼리할 필요성이 줄어듭니다. 이렇게 하면 애플리케이션 성능이 크게 향상될 수 있습니다.
- Pub/Sub 메시징: Redis는 분산 시스템의 구성 요소 간에 실시간 통신을 허용하는 pub/sub 메시징을 지원합니다. 이벤트 기반 아키텍처, 채팅 애플리케이션 등에 사용할 수 있습니다.
- 세션 저장소: Redis는 웹 애플리케이션의 세션 데이터를 저장하는 데 사용할 수 있습니다. Redis에 세션 데이터를 저장하면 사용자 세션 데이터 손실 없이 웹 서버를 수평으로 확장할 수 있습니다.
- 속도 제한: Redis는 속도 제한을 구현하는 데 사용할 수 있습니다. 속도 제한은 사용자가 주어진 시간 내에 만들 수 있는 요청 수를 제한합니다. 이를 통해 악용을 방지하고 모든 사용자가 리소스를 사용할 수 있도록 할 수 있습니다.
- 순위표 및 순위: Redis는 게임 및 기타 애플리케이션의 순위표 및 순위를 구현하는 데 사용할 수 있습니다. 정렬된 세트는 점수와 순위를 저장하는 데 사용할 수 있으며 Redis는 빠른 쿼리를 수행하여 이 데이터를 검색하고 업데이트할 수 있습니다.
요약하면 Redis는 고성능 서비스를 구축하기 위한 강력한 도구입니다. 아키텍처와 기능은 캐싱, 게시/구독 메시징, 세션 스토리지, 속도 제한 및 순위표에 매우 적합합니다. 애플리케이션에서 Redis를 활용하면 성능, 확장성 및 유연성을 개선할 수 있습니다.

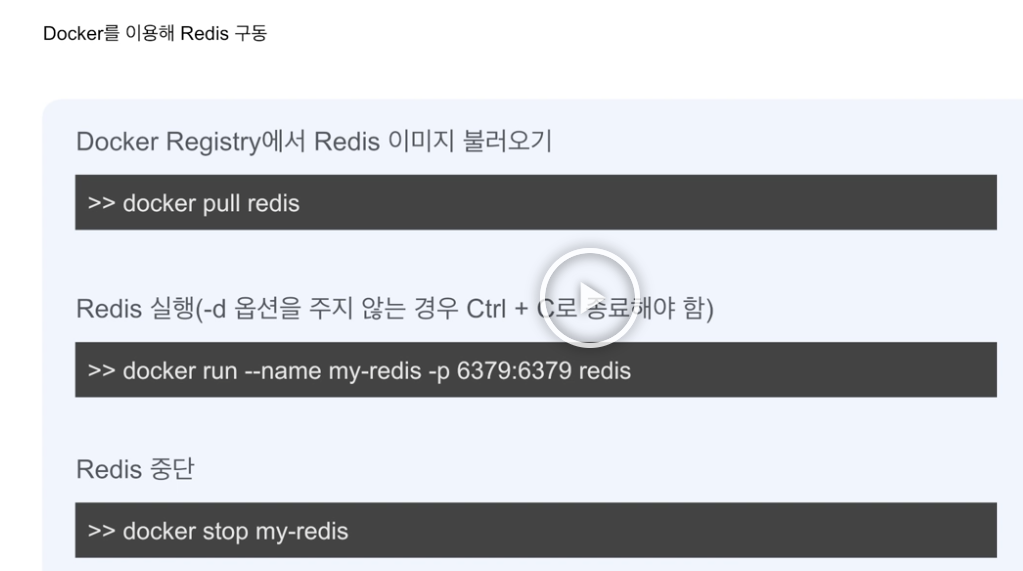
도커로 Redis 관리하기가 좋기 때문에
도커로 Redis 구동합니다.
Redis이미지 불러오기 : docker pull redis
Redis 실행 : docker run --name my-redis -p 6379:6379 redis
Redis 중단 : docker stop my-redis

Part4. 대용량 비동기 프로세스를 위한 Kafka 활용
Apache Kafka는 대량의 실시간 데이터 스트림을 처리하도록 설계된 오픈 소스 분산 이벤트 스트리밍 플랫폼입니다. Kafka는 수평적 확장을 위해 설계되었으며 짧은 대기 시간으로 대량의 데이터를 처리할 수 있습니다. Kafka는 메시지 대기열, 스트림 처리 및 이벤트 소싱을 비롯한 다양한 사용 사례에 사용할 수 있습니다.
카프카 아키텍처:
Kafka는 분산 시스템이므로 여러 노드에서 실행되며 수평으로 확장할 수 있습니다. Kafka는 브로커, 생산자, 소비자 및 주제를 포함한 여러 구성 요소로 구성됩니다.
브로커는 Kafka에서 데이터를 저장하고 관리하는 서버입니다. 생산자는 Kafka 브로커에게 데이터를 보내고 소비자는 Kafka 브로커로부터 데이터를 받습니다. 주제는 데이터가 송수신되는 채널입니다. 주제는 분할되고 각 파티션은 다른 브로커에 저장됩니다. 이를 통해 데이터의 병렬 처리와 Kafka 클러스터의 수평 확장이 가능합니다.
카프카 활용:
Kafka는 대용량 비동기 프로세스를 처리하는 데 매우 적합합니다. 몇 가지 일반적인 사용 사례는 다음과 같습니다.
- 메시지 대기열: Kafka는 분산 시스템의 다른 부분을 분리하기 위한 메시지 대기열로 사용할 수 있습니다. 생산자는 Kafka 주제에 메시지를 보낼 수 있고 소비자는 이러한 메시지를 비동기적으로 소비할 수 있습니다.
- 스트림 처리: Kafka Streams는 실시간으로 데이터의 스트림 처리를 허용하는 라이브러리입니다. Kafka Streams를 사용하면 Kafka 주제의 데이터를 처리하고 결과를 다시 Kafka에 쓸 수 있는 스트림 처리 애플리케이션을 만들 수 있습니다.
- 이벤트 소싱: Kafka는 애플리케이션 상태에 대한 모든 변경 사항을 일련의 이벤트로 캡처하는 이벤트 소싱에 사용할 수 있습니다. Kafka 주제는 이러한 이벤트를 저장하는 데 사용할 수 있으며 소비자는 이러한 이벤트를 처리하여 애플리케이션 상태를 재구성할 수 있습니다.
- 데이터 통합: Kafka는 여러 소스의 데이터를 단일 스트림으로 통합하는 데 사용할 수 있습니다. Kafka Connect는 다양한 소스 및 싱크의 데이터를 쉽게 통합할 수 있는 프레임워크입니다.
- 지표 및 로깅: Kafka는 분산 시스템에서 지표 및 로그를 수집하고 저장하는 데 사용할 수 있습니다. 생산자는 메트릭과 로그를 Kafka 주제로 보낼 수 있고 소비자는 이러한 메시지를 처리하여 시스템 성능을 분석하고 문제를 해결할 수 있습니다.
결론적으로 Kafka는 대용량 비동기 프로세스를 처리하기 위한 강력한 플랫폼입니다. 이 아키텍처는 수평적 확장 및 병렬 처리를 허용하며 해당 기능을 통해 메시지 대기열, 스트림 처리, 이벤트 소싱, 데이터 통합, 메트릭 및 로깅에 적합합니다. 애플리케이션에서 Kafka를 활용하면 대기 시간이 짧은 대용량 데이터를 처리하고 시스템의 확장성과 안정성을 향상시킬 수 있습니다.
'4차산업혁명의 일꾼 > 웹개발' 카테고리의 다른 글
| 파이썬프로그래밍 기초 (0) | 2023.02.23 |
|---|---|
| 디자인패턴 3 - 기능의 선언과 구현을 분리하여 생각하기 (0) | 2023.02.21 |
| 디자인패턴 2 - 하위클래스에 위임하기 : 템플릿 패턴 , 팩토리 패턴 (0) | 2023.02.19 |
| 디자인 패턴 1- 클래스의 인스턴스를 생성 -(Singleton Pattern,Prototype Pattern,abstract Factory Pattern,Builder Pattern : 싱글톤, 프로토타입, 공장, 빌더) (0) | 2023.02.19 |
| 클린코드 - 애자일소프트 장인정신 1 - 5가지 정신 (0) | 2023.02.19 |