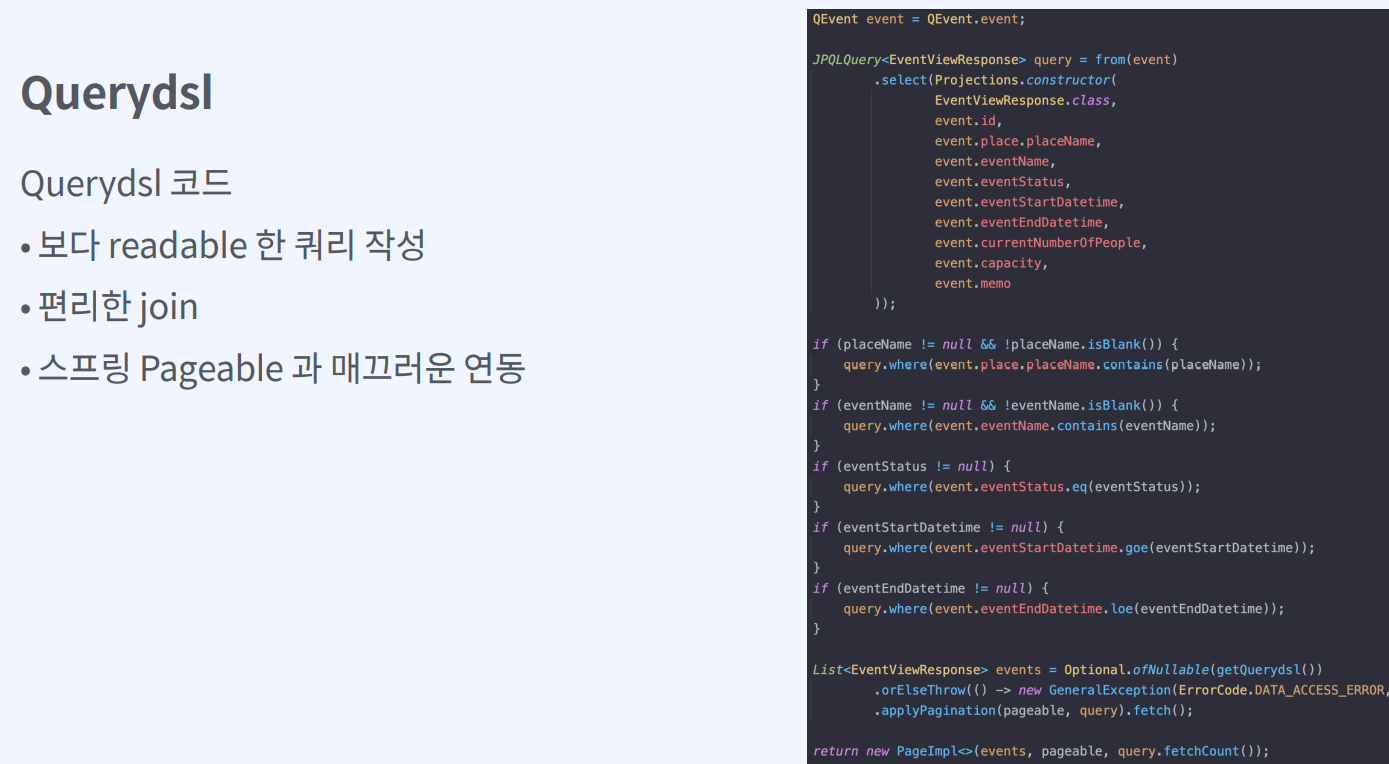
Querydsl은 스프링 Data JPA와 연동이 잘된다.
eager Fetch 의 lazy Fetch 차이

fetch 전략을 짜야 한다.

fetch 전략의 설정
효율성 - 데이터가 어느 쪽으로 더 자주 사용될 것 같은가 예측
• default 내버려두기: 필요한 시점에 최선의 방식으로 데이터를 가져옴
• LAZY 사용: 연관 관계가 있는 엔티티에서 자식 엔티티만 가져오는 시나리오일 때
• 프로그래머가 로직 흐름에서 join 을 의식하고 있지 않음
• LAZY 세팅이 후속 쿼리 발생 방지를 보장하지는 않음
• ex: 불러들인 자식 엔티티가 서비스 레이어 어딘가에서 결국 부모 엔티티 필드를 건드렸을 경우
• EAGER 사용: 연관 관계가 있는 엔티티에서 무조건 다 가져오는 시나리오일 때
• 프로그래머가 join 을 사용해야 하는 상황임을 인지하고 있음
• EAGER 세팅이 join 동작을 보장하지는 않음
ex: Spring Data JPA 쿼리 메소드 findAll()
• JPQL 을 직접 작성해서 join 을 영속성 컨텍스트에 알려줘야 함 (ex: querydsl )
JPA N+1 해결법
3가지 방법
[1] 똑똑한 lazy
1) 비즈니스 로직을 면밀히 분석하여, 불필요한 연관 관계 테이블 정보를 불러오는 부분을 제거
2) 가장 똑똑하고 효율적인 방법
[2] eager fetch + join jpql
1) join 쿼리를 직접 작성하는 방법은 다양(@Query ,querydsl,..)
2) 쿼리 한번에 오긴 하겠지만 , join 쿼리 연산비용과 네트워크로 전달되는 데이터가 클수 있음
[3] 후속 쿼리를 in으로 묶어주기 : N+1 -> 1+1 로 I/O줄일수 있음
1) 하이버네이트 프로퍼티 : default_batch_fetch_size
2) 스프링부트에서 쓰는 법 : spring.jpa.properties.hibernate.default_batch_fetch_size
3) 100~1000 사이를 추천
4) 모든 쿼리에 적용되고 복잡한 도메인에서 join쿼리를 구성하는 것이 골치아플 때 효율적
'4차산업혁명의 일꾼 > Java&Spring웹개발과 서버 컴퓨터' 카테고리의 다른 글
| C++ 프로그래밍 (0) | 2023.01.05 |
|---|---|
| 컴퓨터과학 총정리~! (0) | 2022.12.17 |
| Spring Data JPA 테크닉 (0) | 2022.07.20 |
| 스프링 스케줄러~! (0) | 2022.07.19 |
| 반응형 웹 구현을 위한 미디어 쿼리 CSS (0) | 2022.07.19 |