
자 분산 시스템 기반 대규모 트래픽처리를 하는데...
보통 MAU가 얼마나 회사마다 나오는지 봤다.
named 회사는 1000만이 넘는것 같다.
잘 체감이 안되는 숫자다.

사실 사용자가 많지 않으면 캐시나.. 이런게 필요한다.
자 로그인한 사용자의 맞춤정보를 제공한다.

이커머스까지 가도 커머스에서 컬리나, 11번가 이런데서 대량 200만~800만 정도 된다.

나는 10~50만 정도되는 사이트까지만 다루어봤다.
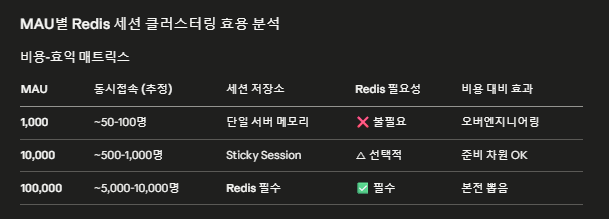
자 10만정도 되면 redis는 필수란다. 천명 정도까지도 사실상 있으면 좋은정도다.

세션 클러스터링 개념은 1000명 정도에서도 필수라고 하니 사실상, 세션클러스터링을 deep하게 알고 , redis는 그 이상을 다룰때를 대비해서 공부한다고 생각해야 한다는 것을 알았다.

그리고 만명정도 부터 캐시가 좋고 , 10만 부터 캐시는 필수... 천명정도에서는 캐시 별 필요없었다..
사용자 인증 기능 구현 : 로그인한 사용자를 식별하여 맞춤 정보를 제공하는 시스템
- 안전하고 효율적인 로그인 인증 메커니즘을 스프링의 세션 기반 인증부터 시작하여 Redis 기반 세션으로 개선하는 과정
- 인증된 사용자의 고유성을 활용하여 장바구니와 같은 사용자별 데이터를 다루는 핵심 기술 역량

1일차. HTTP Session과 Session Clustering

1. Sticky Session( 소규모, 서버 2-3대 ), Session Replication( 중규모, 장애 허용 필요 , 노드 5개이하), Centralized Session Store( 대규모, MSA, K8s ) 와 같은 세션 클러스터링 전략
2. 단일 서버와 분산 서버 환경에서 세션 데이터 관리의 차이점
3. Redis를 활용하여 세션 데이터를 중앙에서 관리하고, 로드 밸런싱 환경에서 세션 공유를 구현하는 방법

트랜잭션과 인덱스 설계 학습
2일차. 인메모리 저장소 및 Redis 데이터 타입 활용
1. 초고속 데이터 액세스를 위한 인메모리 저장소의 원리를 이해하고, 문자열(String), 리스트(List), 집합(Set), 해시(Hash), 정렬된 집합(Sorted Set) 등 Redis의 5가지 핵심 데이터 타입의 구조와 특성
2. 데이터 입력, 조회, 삭제 및 만료 설정과 같은 기본 명령어를 실습하는 동시에, KEYS, FLUSHALL 등의 관리 명령어 사용법
- 캐싱: 자주 찾아보는 데이터를 메모리에 미리 저장해두면, 웹사이트나 앱이 훨씬 빠르게 반응할 수 있어요.
- 세션 관리: 사용자가 로그인했을 때의 정보나 장바구니 내용 같은 세션 데이터를 메모리에 저장해서 빠르게 처리할 수 있죠.
- 실시간 데이터 처리: 주식 시세, 게임 랭킹, 실시간 알림처럼 순식간에 변하는 데이터를 바로바로 분석하고 처리하는 데 아주 유용해요.
주요 인메모리 저장소 시스템
1. Redis
Redis는 다양한 데이터 타입을 지원하는 오픈소스 인메모리 데이터 저장소예요. 단순히 키(Key)와 값(Value)만 저장하는 것을 넘어, 리스트, 해시, 집합 등 여러 가지 형태로 데이터를 저장하고 다룰 수 있는 만능 재주꾼이죠.
Sorted Set (정렬된 집합)
특징:
- 값(Value)과 함께 숫자 형태의 점수(Score)를 저장하는 데이터 구조예요.
- 저장된 요소들은 이 점수를 기준으로 항상 오름차순 또는 내림차순으로 자동 정렬돼요.
- 중복된 값은 허용하지 않지만, 중복된 점수는 허용해요. (점수가 같으면 값이 사전식으로 정렬)
- 특정 점수 범위나 순위 범위에 해당하는 데이터를 효율적으로 조회할 수 있어요.
주요 용도:
- 순위 관리 (리더보드): 게임 점수, 사용자 랭킹, 인기 게시글 순위 등 점수를 기반으로 순위를 매겨야 하는 시스템에 가장 이상적이에요.
- 시간 기준 정렬 데이터 관리: 이벤트 발생 시간, 메시지 전송 시간 등을 점수로 사용하여 시간 순서대로 데이터를 정렬하고 조회할 때 활용돼요.
2. Memcached
Memcached는 단순한 키-값 형태의 데이터를 저장하는 데 특화된 가볍고 빠른 분산 캐싱 시스템이에요. 복잡한 기능보다는 메모리 효율성과 순수한 성능에 집중한 녀석이죠.

3일차. Redis 캐싱 전략 실습
1. 캐싱(Caching)의 기본 원리를 이해하고, 시스템 성능을 극대화하는 다양한 캐싱 전략을 심층적으로 다룹니다
Cache-aside (캐시-어사이드)는 가장 널리 사용되고 직관적인 캐싱 패턴이에요. 애플리케이션 코드가 캐시와 데이터베이스 사이에서 데이터를 직접 관리하는 방식이죠.
Write-through (라이트-스루)는 데이터를 변경할 때 캐시와 원본 데이터 소스(데이터베이스)에 동시에 데이터를 기록하는 패턴이에요. 캐시와 데이터베이스 간의 강력한 데이터 일관성을 보장하는 데 중점을 둡니다.( 데이터 일관성이 매우 중요한 시스템)
Write-back (라이트-백)은 데이터를 변경할 때 일단 캐시에만 빠르게 데이터를 저장하고, 원본 데이터 소스(데이터베이스)는 나중에 비동기적으로 업데이트하는 패턴이에요. 쓰기 성능을 극대화하는 데 초점을 맞춥니다. ( 쓰기 빈도가 매우 높고 실시간으로 데이터 손실이 조금 발생해도 무방한 시스템)
Write-around (라이트-어라운드)는 데이터를 변경할 때 캐시를 완전히 우회하여 오직 원본 데이터 소스(데이터베이스)에만 데이터를 저장하는 패턴이에요. 캐시는 오로지 읽기 성능 향상에만 기여하고 쓰기 작업에는 관여하지 않습니다. ( 쓰기 요청은 많지만, 해당 데이터를 즉시 읽어올 필요는 적은 시스템)

Redis 명령어:
- SET key value EX seconds: key를 value로 설정하면서 seconds초 후에 자동으로 만료되도록 설정합니다.
-
SETEX key seconds value 와 동일한 역할을 하는 약어 명령어입니다.
-
EXPIRE key seconds : 이미 존재하는key에 seconds 초의 만료 시간을 설정합니다.
LRU (Least Recently Used) 및 LFU (Least Frequently Used) 정책
1. Redis는 인메모리 저장소이므로, maxmemory설정으로 지정된 최대 메모리 용량에 도달했을 때 추가적인 데이터를 저장하려면 기존의 일부 데이터를 삭제(Eviction)해야 합니다.
LRU (Least Recently Used) 정책:
- 설명: 가장 오랫동안 사용되지 않은(참조되지 않은) 데이터를 우선적으로 제거하는 정책이에요. 최근에 사용된 데이터는 다시 사용될 가능성이 높다는 가설에 기반합니다.
LFU (Least Frequently Used) 정책:
- 설명: 사용 빈도(참조 횟수)가 가장 낮은 데이터를 우선적으로 제거하는 정책이에요. 오랫동안 사용되지 않았어도 자주 사용되는 데이터라면 유지하고, 최근에 사용되었더라도 사용 빈도가 낮으면 제거합니다.
4일차. Redis 세션 기반 사용자 인증 실습
1. 스프링 시큐리티(Spring Security), 스프링 세션(Spring Session), 그리고 레디스(Redis)를 활용해 REST API의 인증 시스템을 구축하는 방법
2. 스프링 시큐리티를 사용해 REST API의 인증 및 권한 부여를 구현하고, 스프링 세션과 레디스를 연동하여 세션 정보를 외부화하며, 다중 서버 환경에서 세션을 공유하는 원리를 이해
인메모리 저장소 데이터 영속성 문제
스프링 세션 (Spring Session), HTTP Basic 인증 ....
쭈욱 배우다가.. .이게 적어도 만명이상에서 부터 효용성이 발휘된다고 하니.. 부하테스트를 직접 해봐야 하는 생각이든다.
'Software > Maker(Spring & Python & node)' 카테고리의 다른 글
| 2026년 전자정부프레임워크의 방향과 JSP의 운명: SI 개발자가 알아야 할 현실 (0) | 2026.04.10 |
|---|---|
| 백엔드 API의 응답이 느려 사용성에 악영향이 발생하는 상황에서 어떻게 대응하실 건가요? (0) | 2026.04.10 |
| AI 연구실: Gemma 4 31B 모델을 3070 환경에서 돌리는 법 (0) | 2026.04.10 |
| 무료 Gemma 4(Gemini 계열)와 유료 Claude 4.6(Sonnet/Opus) 비교 (1) | 2026.04.10 |
| OSIV(Open Session In View) 옵션에 대해서 설명해주세요. (0) | 2026.04.10 |