
1. 스프링AI - 인공지능의 개념과 스프링AI
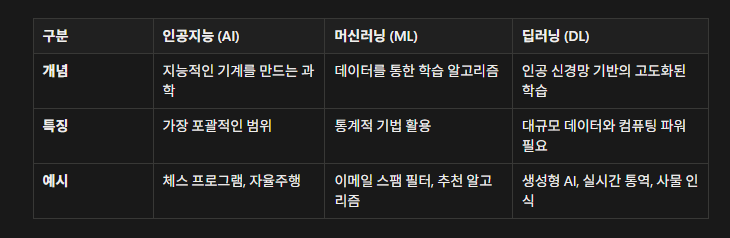
이런 인공지능의 개념을 이해하면... 인공지능이 포괄적인게 개념이 잡힌다. 인공지능은 말그대로 어떤 목적.. 체스게임의 경우 체스룰안에서의 승리.. 자율주행은... 도로 위에서 안전한 운전(여러가지 경우의수의 판단, 핸들제어, 앞차와의 거리 등)을 위한 수많은 판단이다... 이게 사실 제일어려워 보인다. 그러나 이게 가능해지면서 과거 전투기나 이런 비싼 장비가 하던것을 드론이나 이런 저비용으로 상당한 퍼포먼스를 실제 우크라이나 전쟁에서 보고 있는등.. 이제 인공지능 사용능력은 이제 필수품이 된것 같다. 왜냐하면 과거 기계가 가공할 성능으로 수많은 일자리를 몰아내면서.. 기계파괴운동까지 있었다. 이것은 그러나 변리사, 변호사, 회계사 이런 전문직 들의 지능을 아주 평범하게 만들어 버린다. 누구나 gpt의 도움이면 간단한 법률지식, 회계지식을 얻는게 너무 쉬워졌다. 이건 결국 과거 사농공상 시대의 선비들의 자부심으로 내세운 수많은 책들을 얻은 지능을 아주 싸구려로 만들어 버린다. 그래도 변하지 않는건 인간세계의 지혜와 공의와 정의와 정직에 관해 인간스스로 기준을 세우고 판단해야 한다는 것이다.
머신러닝은 통계기반으로 데이터를 학습해서 말한다고 하면 그냥 사주팔자가 나온 중국에서 온서적이나 기타 등등.. 여러 통계를 활용한 데이터 기반의 추측 및 판단이다.. 사실 여기까지 이미 머신러닝이 했고... 이 머신러닝은 인공지능과 딥러닝에 비하면 이미 기존에 보이던 것들이다.
딥러닝은 인공신경망 기반으로 고도화된 학습인데 ... 여기는 gpt 같이 엄청난 성능을 보여주지만.. 역시나 지금 엔비디아 주가와 gpu를 태운 블록체인 현상에서 보듯이 장비빨이 필요하다. 엄청난 돈이 필요한 것이다. 즉 인프라적으로 자본면에서나 대기업 등 기타 경우의 수에서 상당히 불리하다. 그러나 gpt, gemini, claude의 가공할 성능면에서 모듯이 개발자 측면에서 가장 쉽게 접근이 가능하고.. 이로인해 코드 생성의 비용이 0에 수렴할정도로 클로드 코드가 가공할 생산성을 보이고... 과거 집단지성의 지혜라고 정치권에서 한목소리 내던것을 ... 딥러닝을 통한 기술이.. 이미 웬만한 집단지성이 글로벌적인 마스터급 일반론이 보편화 되고 있다. 멀티미디어... 시스템... 컴퓨터에서 보이던 이미지, 동영상,텍스트 이런것들을 너무 쉽게 만든다.. 이제 어떻게 차별화 시키는가가 인간의 과제가 되어가고 있다.
결국 이 딥러닝 기술이나 머신러닝 기술을 어찌 사용하나가.. 수많은 판도를 바꿀것이다.
그중에 스프링AI는 LLM을 다룬다~! 자... LLM의 원리 질의문... 바이브 코딩을 한다고 해보자...
스프링부트가 모지?
를 물으면 이것을 쪼개서 메모리에 저장하는데 그 메모리 하나가 토큰(Token)이라는 형태로 나눈다고 할수 있다고 한다. 스프링 , 부트 , 란, 모지, ? 이렇게 바이브로 프롬프트가 가자마자 5개 정도의 토큰으로 메모리를 점유하며 나뉘는것이다. (위의는 예시이며 다른식으로 형태소를 쪼개는데 한국어는 Nori 형태분석소를 쓴다고 하니 그 기준이 있을듯하다.)
그 와 별개로 비용산정을 하면 저 토큰(메모리 점유)하나가 결국 비용으로 청구된다.
자 그 다음단계 임베딩.. 컴퓨터는 본질적으로 0,1이니 당연히 언어를 모른다. 이것을 계산하려면 자기들이 연산하는 방식인 숫자로 계산해야 한다. 즉 스프링이라는 단어에 수많은 벡터값을 가지고 이에 따라서 단어들 사이에 상관관계를 분석한다. 그에 따른 가중치를 숫자로 표현해 놓고 있다... 이것을 좌표상에 강아지와 개는 가깝고 자동차는 멀다... 흠... 이렇게 수많은 상관관계를 쪼개 연산하니.. 벡터db가 필요한듯하다.
이 벡터 데이터가 LLM으로 가는순간 트랜스 포머블록으로 들어간다. 트랜스포머... selft-attention 즉.. 인간세계로치면 문맥기반.. 상화파악하는 과정속도다. feed forward는 어느정도 문맥과 상황파악을 했으면... 그것에 대해 답변할만한 지식이 있어야 한다.

이 feed forward는 각 토큰(단어)의 위치에서 독립적으로 전형되는 비선형 신경망이다. 보통 두개의 선형 변환(Linear Layer)와 그 사이의 활성화 함수(주로 ReLU 또는 GELU)로 구성된다. 입력받은 데이터를 훨신 더 큰 차원으로 확대한뒤(Expansion), 핵심 정보를 남기고 다시 원래 차원으로 압축(Projection)한다.
결국 핵심 역할은 지식의 저장소 및 정제로 방대한 데이터 중에 문맥과 상황에 맞는 적절하고 적합한 정보를 불러온다. 비선형성으로 인해 단순하지 않고 활성화 함수로 복잡한 논리를 처리한다.
즉 self-attention이 단어들을 서로 연결했다면, 피드 포워드는 각 단어의 벡터를 개별적으로 강화한다. 즉 self-attention은 상황과 문맥을 파악하기 위해 전문가들이 토론하고, feed-forward는 그 전문가들이 자신의 자리로 돌아가 지식을 총동원해서 적절한 답을 도출하기 위해 정리하는 것이다.
LLM은 문장을 한번에 완성하지 않고 다음에 올 가장 확률 높은 토큰을 하나씩 찾아낸다. 확률분포계산은 학습된 방대한 데이터를 방탕으로 후보군을 뽑고 선택한다. 즉 LLM은 본질적으로 다음에 올 가장 그럴싸한 단어를 맞히는 기계다.
이 다음 토큰 예측은 트랜스 포머 구조의 가장 마지막층인 출력층(Output Layer)에서 일어난다.
트랜스포머 블록의 통과 : 앞서 설명한 4단계 (Attention, Feed Forward)를 거치면, 모델 내부에는 문맥정보가 가득 담긴 추상적인 숫자 뭉치(벡터)가 생성된다. 선형 층 (Linear Layer)가 이 숫자 뭉치를 모델이 알고 있는 전체 단어 사전의 개수 만큼 넓게 펄쳐진다. 그리고 선형층에서 이 숫자벡터를 모델이 알고 있는 전체 단어 사전의 개수 만큼 넓게 펼친다... 국어사전/백과사전이 들어가 있었다.. (5만개의 단어면 5만개의 칸)
소프트맥스 함수는 펼쳐진 숫자들을 0에서 1사이의 확률값으로 변환한다. 모든 후보 단어의 확률합은 100%가 된다. (ex: Java:0.6, 프레임워크 :0.25, 무엇 : 0.1 ) 디코딩 전략으로 이 확률 분포에서 최종적으로 어떤 단어를 뽑을지 결정한다. 디코딩 전략은 이 확률 분포에서 최종적으로 어떤 단어를 뽑을지 결정한다. Greedy Searh는 무조건 확률이 가장 높은것만 선택하고 Sampling은 약간의 확률이 있는 다른 단어도 섞어서 더 창의적인 답변을 유도한다.
결국 셀프어텐션은 상황파악해서, 피드포워드로 맞는 지식을 찾아내고, 최종 출력층에서 적절하다고 추린 답이 나온다.
이렇게 지속적으로 판단해서 답을 만든다.

Spring Boot란 무엇인가? 에 대한 답변을 결국,
"Spring Boot는 Java 기반의 오픈소스 프레임워크입니다."
그 추린답에 대한 판단은 인간의 몫인데... 이런거는 아주 국어사전/백과사전 기본지식에 속해서 틀리지 않는듯 하다.
LLM은 사용자의 질문을 받으면 내부적으로 [텍스트 → 숫자 → 문맥 분석 → 확률 계산 → 다시 텍스트]의 정교한 변환 과정을 거칩니다.
자 아까 점유했던 단어기반의 메모리 점유 , 즉 토큰
이것은 비용이다.
최근 핫한 클로드는

이렇다고 한다. 2배 성능에는 3배가격, 4배 성능에는 5배 가격이 적용된다.
최고성능을 자랑하는 opus지만, 비용효율면에서는 sonnect이 낫다.
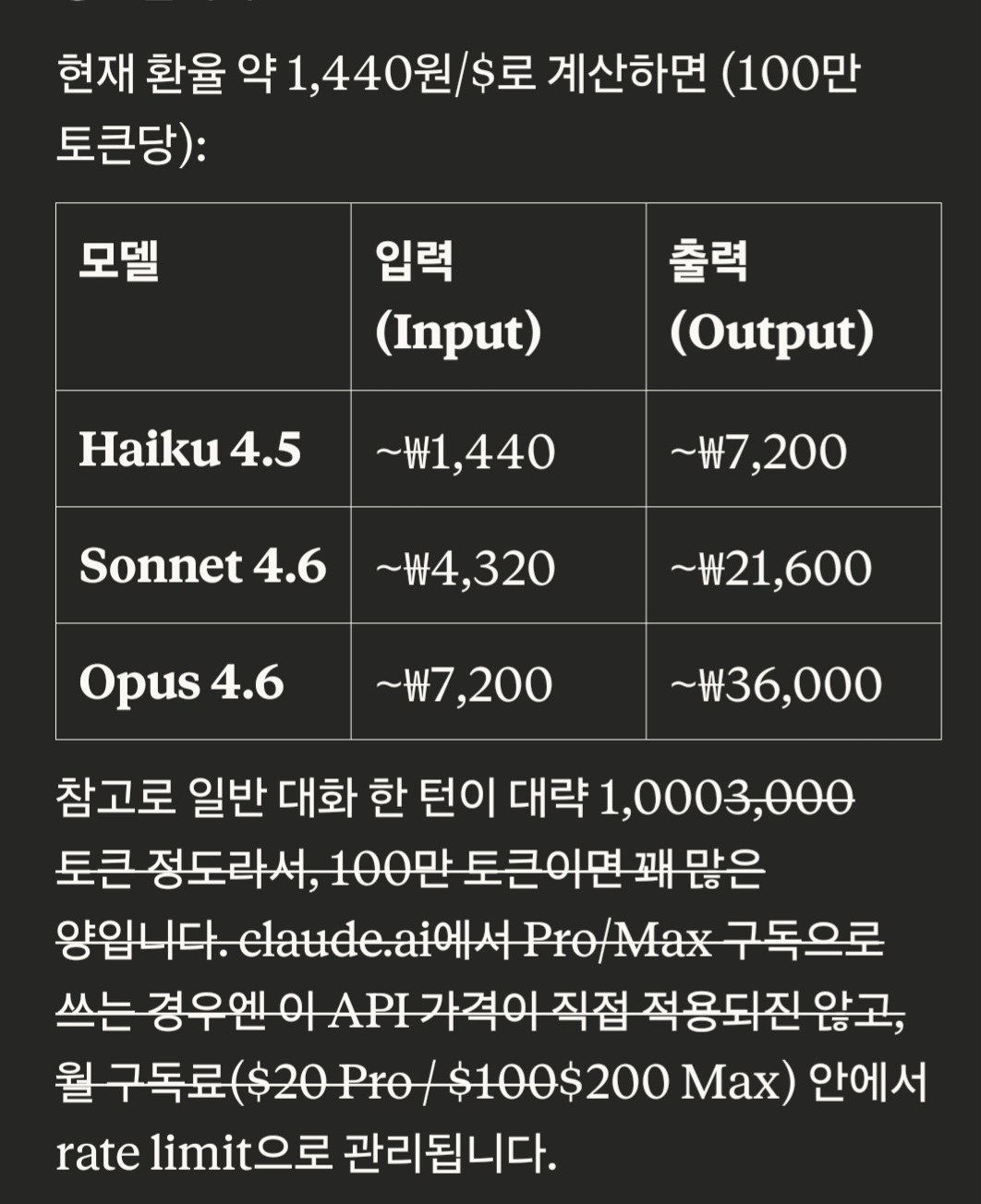
max 플랜은 200$인데... 200$이상을 쓰면 일단... api 비용 기준으로 넘어가면 잘쓰고 있는것인가... 이런생각을 해본다.
그러나 api가 아니라 그냥 쓰면 200$로 opus나 sonnect을 마음껐 쓸수있는듯하다. 문맥도 1M.. 즉 100만 토큰을 기억할수 있는 클로드다. 이 100만 토큰 비중으로 api 비용이 계산된다는데 이게 보통 한 컨텍스트에서 생성형 ai 가 메모리에 가용하는 용량이라고 한다. 이게 꽉차면... 새로운 상황맥락이 없는 대화가 시작되는 것이다.
api 사용시 한글보다 영어, 입력/출력형식을 정제하고 간단하게 하는 등의 기법을 써서 절약할수 있다고 한다.
자 이제 코드단으로 가면 코드 한줄수정으로 claude의 저 모델들을 교체할수 있다. 모델들은 추상화 되어 있어서 아주 편리하게 사용할수 있다. ChatClient를 빈으로 등록하여 스프링의 DI기능을 잘 활용할수 있다. AOP기능을 통해 보안,로깅,트랜잭션처리 관리도 할수 있다.

자 그리고 벡터 store를 지원하는 pinecone, redis, postgresql를 쓸수 있다. rag(검색 증강생성)은 외부 지식을 ai에게 전달하는 복잡한 파이프라인을 쉽게 설계 구축할수 있게 설계되어 있다.
자 이 모두 스프링 AI를 쓰면 아주 간단하게, 엔터프라이즈급 AI서비스를 빠르게 구축할수 있게 해준다.
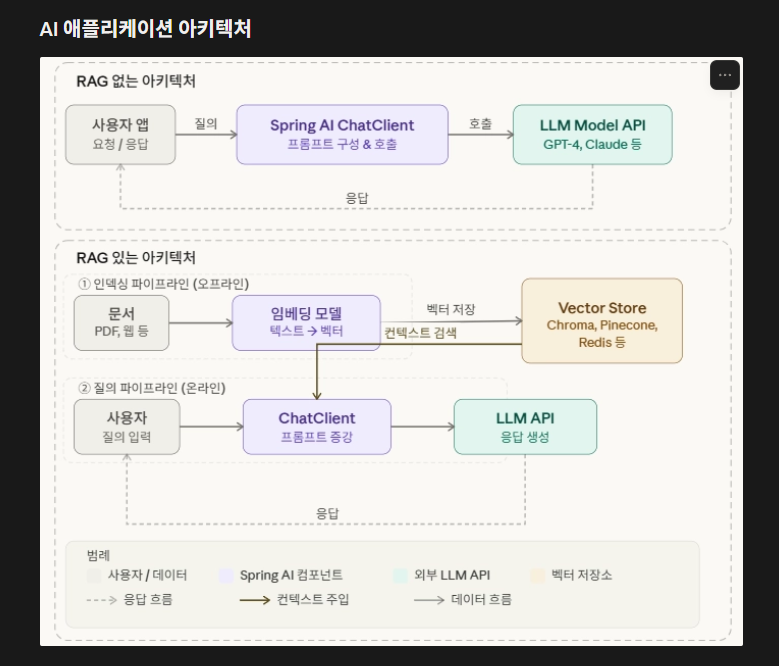
정말 간단하게 API key만 하면 , 비즈니스로직도 간단하게 해서 데이터베이스 연동까지 된다. 비용관리를 위해 처리량 제한을 걸수 있고 캐싱을 통해 API비용을 획기적으로 줄일수 잇다.

위의 내용은 프롬프트 템플릿을 만들어 사용자가 개떡같이 말해도 찰떡같이 알아듣고 대답하게 할수 있다.
백엔드 통합 방식 : 백엔드 통합의 5가지 핵심 장점 (✅ 권장)
브라우저는 우리 서버(Spring Boot)에 요청을 보내고, 서버가 안전하게 AI API와 통신하는 구조입니다.

1.보안 및 자산 보호
@Service
public class ChatService {
@Value("${spring.ai.openai.api-key}")
private String apiKey; // 서버 외부로 절대 유출되지 않음
}
API Key를 서버 내부(환경 변수, Secrets Manager)에 숨깁니다. 사용자에게는 절대 노출되지 않습니다.
2.정교한 비용 및 사용량 관리
public String chatWithLimit(String userId, String message) {
if (usageService.getTodayUsage(userId) >= 10) {
throw new UsageLimitException("오늘 사용량을 모두 소진했습니다.");
}
return chatClient.prompt().user(message).call().content();
}
- 사용자별 일일 호출 횟수를 제한하여 예기치 못한 비용 지출을 방지합니다.
3.개인화된 비즈니스 로직
예: "이 고객은 30대 남성이고 최근 등산화를 구매했어. 이 정보를 바탕으로 상품을 추천해줘."
@Service
public class ProductRecommendationService {
@Autowired
private UserRepository userRepository;
@Autowired
private ProductRepository productRepository;
public String recommendProduct(Long userId, String query) {
// 1. DB에서 사용자 정보 조회
User user = userRepository.findById(userId)
.orElseThrow(() -> new UserNotFoundException());
// 2. 사용자 구매 이력 조회
List<Product> purchaseHistory = productRepository
.findByUserId(userId);
// 3. 개인화된 프롬프트 생성
String prompt = String.format("""
다음 사용자에게 상품을 추천해주세요:
- 연령대: %s
- 관심사: %s
- 구매 이력: %s
- 질문: %s
""",
user.getAgeGroup(),
user.getInterests(),
purchaseHistory.stream()
.map(Product::getName)
.collect(Collectors.joining(", ")),
query
);
// 4. AI 호출
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}
DB에 저장된 사용자 프로필, 구매 이력 등을 프롬프트에 결합하여 "나만을 위한 답변"을 생성합니다.
4. 응답 품질 관리 및 모니터링
@Service
public class ManagedChatService {
public String chat(String message) {
// 1. 입력 검증
if (containsInappropriateContent(message)) {
return "부적절한 내용이 포함되어 있습니다.";
}
// 2. 프롬프트 템플릿 적용 (일관된 응답 품질)
String enhancedPrompt = """
당신은 전문적이고 친절한 고객 지원 AI입니다.
다음 규칙을 따르세요:
1. 존댓말 사용
2. 3문장 이내로 답변
3. 확실하지 않으면 "정확한 답변을 드리기 어렵습니다"라고 답변
사용자 질문: %s
""".formatted(message);
try {
// 3. AI 호출
String response = chatClient.prompt()
.user(enhancedPrompt)
.call()
.content();
// 4. 로깅 (모니터링)
log.info("AI 호출 - 입력 토큰: {}, 출력 토큰: {}, 비용: ${}",
inputTokens, outputTokens, cost);
return response;
} catch (Exception e) {
// 5. 에러 처리
log.error("AI 호출 실패", e);
return "죄송합니다. 일시적인 오류가 발생했습니다.";
}
}
}
- 사용자가 대충 질문해도 백엔드에서 '전문가 페르소나'를 입혀 높은 품질의 답변을 유도합니다. 또한, AI가 답한 내용에 부적절한 표현이 있는지 검증한 뒤 사용자에게 전달합니다.
@Service
public class ManagedChatService {
public String chat(String message) {
// 1. 입력 검증
if (containsInappropriateContent(message)) {
return "부적절한 내용이 포함되어 있습니다.";
}
// 2. 프롬프트 템플릿 적용 (일관된 응답 품질)
String enhancedPrompt = """
당신은 전문적이고 친절한 고객 지원 AI입니다.
다음 규칙을 따르세요:
1. 존댓말 사용
2. 3문장 이내로 답변
3. 확실하지 않으면 "정확한 답변을 드리기 어렵습니다"라고 답변
사용자 질문: %s
""".formatted(message);
try {
// 3. AI 호출
String response = chatClient.prompt()
.user(enhancedPrompt)
.call()
.content();
// 4. 로깅 (모니터링)
log.info("AI 호출 - 입력 토큰: {}, 출력 토큰: {}, 비용: ${}",
inputTokens, outputTokens, cost);
return response;
} catch (Exception e) {
// 5. 에러 처리
log.error("AI 호출 실패", e);
return "죄송합니다. 일시적인 오류가 발생했습니다.";
}
}
}
5. 성능 최적화 (캐싱)
@Service
public class CachedChatService {
private final Cache<String, String> cache =
Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build();
public String chat(String message) {
// 동일한 질문은 캐시에서 반환 (비용 절감)
return cache.get(message, key -> {
return chatClient.prompt()
.user(key)
.call()
.content();
});
}
}
Prompt Template 활용
프롬프트에 매번 같은 문구를 반복 입력하는 것은 비효율적입니다. Prompt Template은 프롬프트의 구조(뼈대)와 가변 데이터(변수)를 분리하여 재사용성을 극대화합니다.
- 플레이스홀더: {variableName} 형식을 사용하여 동적 데이터를 삽입합니다.
- 장점: 비즈니스 로직(Java)과 프롬프트 엔지니어링(Text)을 깔끔하게 분리할 수 있습니다.
실습 예제: 마케팅 문구 생성 서비스
@GetMapping("/marketing")
public String generateMarketing(
@RequestParam(value = "productName") String productName,
@RequestParam(value = "features") String features) {
String template = """
제품명 {productName}의 마케팅 문구를 작성하세요.
주요 특징: {features}
조건: 감성적이고 100자 이내로 작성할 것.
""";
return chatClient.prompt()
.user(u -> u.text(template)
.param("productName", productName)
.param("features", features))
.call()
.content();
}
System Message를 활용한 역할 정의
AI에게 '전문가'라는 페르소나를 부여하면 답변의 품질이 비약적으로 향상됩니다. System Message는 AI의 행동 지침과 배경 지식을 설정하는 데 사용됩니다.
- 우선순위: 모델은 사용자 메시지보다 시스템 메시지의 지침을 더 근본적인 규칙으로 인식합니다.
- 활용: 말투 설정(존댓말/반말), 금기 사항 설정, 특정 분야 전문가 설정 등.
System Message 활용 예제:
@GetMapping("/translate")
public String translate(
@RequestParam(value = "text") String text,
@RequestParam(value = "targetLanguage", defaultValue = "영어") String targetLanguage) {
return chatClient.prompt()
// 1. AI의 페르소나 설정 (System Message)
.system("당신은 전문 번역가입니다. 주어진 텍스트를 문맥에 맞게 자연스럽게 번역해주세요.")
// 2. 동적 파라미터 주입 (Prompt Template)
.user(u -> u.text("다음 텍스트를 {lang}로 번역해주세요: {text}")
.param("lang", targetLanguage)
.param("text", text))
.call()
.content();
}

return chatClient.prompt()
// 1. 시스템 메시지로 AI의 성격 고정 (고정값)
.system("너는 맛집 추천 전문가야. 답변은 항상 '반말'로 친근하게 해줘.")
// 2. 프롬프트 템플릿으로 사용자 입력 가공 (변수 사용)
.user(u -> u.text("오늘 {location} 근처에서 {food} 맛집 3곳 추천해줘.")
.param("location", "강남역")
.param("food", "삼겹살"))
.call()
.content();
텍스트 응답 vs 구조화된 응답 비교
LLM(거대언어모델)은 기본적으로 '자연어(Text)'를 출력하도록 설계되어 있습니다. 하지만 우리가 만드는 백엔드 서비스는 '객체(Object)'나 '데이터(Data)'를 필요로 합니다. 이 간극을 메워주는 것이 바로 구조화된 응답 기능입니다.
일반 응답 (String):
"이 리뷰는 긍정적입니다. 점수는 8점이고, 제품 품질이 우수합니다."
구조화된 응답 (Java Object):
ProductAnalysis {
sentiment = "positive",
score = 8,
summary = "제품 품질이 우수합니다"
}
// ❌ 기존 방식 - 문자열 파싱
String response = chatClient.prompt()
.user("이 리뷰를 분석해주세요: " + review)
.call()
.content();
// 결과: "긍정적이며, 8점입니다. 품질이 좋습니다."
// 문제점:
// 1. 파싱 로직이 복잡함
// 2. 형식이 일정하지 않음
// 3. 타입 안정성이 없음
// 4. 에러 처리가 어려움
String sentiment = extractSentiment(response); // 😰 복잡한 파싱
int score = extractScore(response); // 😰 에러 가능성
// ✅ 권장 방식 - 타입 안정성 확보 및 파싱 자동화
ProductAnalysis result = chatClient.prompt()
.user("이 리뷰 분석해줘: " + review)
.call()
.entity(ProductAnalysis.class); // Spring AI가 JSON 스키마 강제 및 파싱을 알아서 수행
int score = result.getScore(); // 😃 안전하게 바로 사용!

변하는 것 (Transient Technology)
도구와 프로토콜: MCP(Model Context Protocol), 특정 라이브러리, 프레임워크 등은 기술적 수단일 뿐이며 언제든 더 효율적인 것으로 대체됩니다. 여기에만 매몰되면 기술의 변화에 휩쓸리게 됩니다.
변하지 않는 것 (Immutable Essence)
컴퓨터 공학의 정점: 인간이 복잡한 로직을 하나하나 코딩하지 않아도, AI가 스스로 판단하고 수행할 수 있다는 '지능의 자동화'라는 본질은 변하지 않습니다.
문제 해결: 기술이 무엇이든 결국 "사용자의 문제를 해결하고 가치를 창출한다"는 서비스의 목적은 불변합니다.
기술을 선택할 때 이 질문을 해보세요.
- 이 기술이 1년 후에도 존재할 것인가?
- 이 기술이 바뀌면 우리 서비스의 핵심 가치도 바뀌는가?
- 우리가 해결하려는 문제의 본질은 무엇인가?
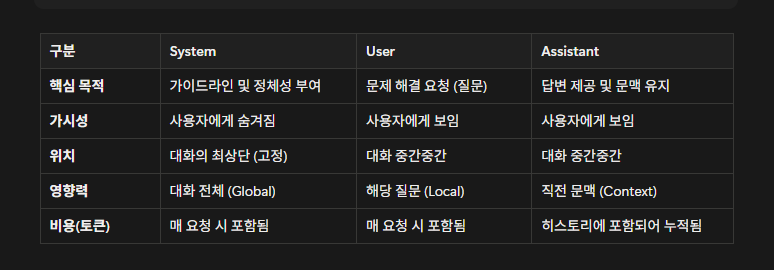
LLM을 배우다 보면 좀 복잡하다.. 시스템, user,assitant 흠...
제미나이가 멀티모달에 좋다고한다. 모... 유투브도 있고...

로컬환경에서 LLM모델을 연결해보자
먼저 GPU 없이 CPU만으로도 원활한 실행이 가능한 Ollama의 설치 및 운영체제별 설정 방법을 익히고, 한국어 성능이 뛰어난 경량화 모델인 Alibaba Qwen3를 로컬에 직접 구축하여 다국어 처리 역량을 테스트합니다.
최종적으로는 Spring AI 프레임워크를 활용해 설정부터 컨트롤러 구현까지의 전 과정을 실습함으로써, 클라우드 API를 사용하는 것과 동일한 방식으로 Spring Boot 애플리케이션에 로컬 LLM을 완벽히 통합하는 기술을 습득하게 됩니다.
로컬환경 LLM모델 연결
gpu말고 cpu만으로 원활한 실행이 가능한 Ollama ( AI 모델계의 Docker) 라는 녀석을 설치하고 운영하는것은 처음해본다.
로컬저장이라 보안이 좋고 비용이 절감되는 장점이 있다.
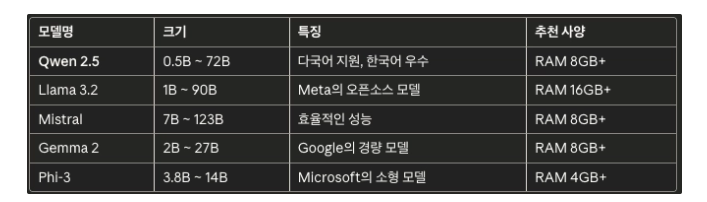
사양은 일단 이렇다... 크기 작고 한국어가 우수한데 8GB이상이면 되니 괜찮은듯 하다.
meta의 Llama를 알고 있었는데 구글의 Gemma 그리고 Microsoft의 Phi-3은 처음본다. 그리고 Qwen2.5와 Mistral 은 어떨까?
일단 여기서 Qwen이 작고 저사양에서도 돌아가고 다국어지원에 한국어 우수라 추천한듯하다.
# Ollama 컨테이너 실행 (데이터 보존을 위한 볼륨 설정 및 포트 매핑)
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
설치도 쉽다...
docker exec -it ollama ollama run qwen2.5:3b 성능확인도 해봤다..
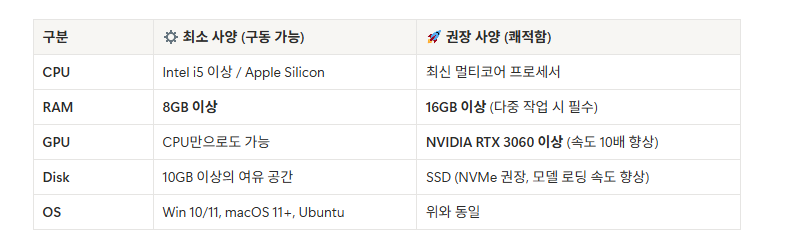
익히 들어온 하드웨어와 gpu 빨이다... 권장사양을 보니 속도가 10배향상, 16GB는 다중작업 필수 SSD와 OS는

클로드는 이런데...

올라마에서... 비용절감과 효율성을 위해 튜닝설정을 좀해야 한다.

미니 테스트로 좋은 올라마.. 도커스럽다... 어쨌건 llm도 cpu만으로 테스트할수 있었다!!
'Platform > Software Orchestration' 카테고리의 다른 글
| 프롬프트 몇 줄이 모델을 바꾼다 — Few-Shot Learning이 AI 활용의 핵심인 이유 (0) | 2026.03.26 |
|---|---|
| AI 오케스트레이션, 이제는 "잘 돌아가는 것"이 아니라 "안전하게 통제되는 것"이 핵심이다 (0) | 2026.03.26 |
| Claude Code 에이전트는 결국 IaC다 (0) | 2026.03.26 |
| Spring AI는 LangChain의 대체인가? — 2026년 기준 Java AI 프레임워크의 현실적인 평가” (0) | 2026.03.23 |
| “Spring AI는 LangChain의 카피인가? — 프레임워크 철학으로 보는 진짜 차이” (0) | 2026.03.23 |