
[왕초보] 마케터, 기획자를 위한 실전 데이터 분석 3주차[파이썬,python] -스파르타코딩클럽

가장 적절한 고객 관리 타이밍은? 전처리

import pandas as pd
sparta_data = pd.read_table('/content/access_detail.csv',sep=',')
sparta_data.head()
print(type)
#파이썬의 type()함수를 쓰면, 데이터의 종류를 확인 할수 있어요 :)
print(type(sparta_data['access_date'][1]))
#sparta_date 정보에서 access_date 열에서 데이터 첫번째 부분만 확인 하면 되겠죠?
# 날짜 포맷으로 변경
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
#[날짜 컬럼].dt.day_name 으로 해당 날짜의 요일을 가져 올수 있어요!
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
sparta_data.tail(5)
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
#week의 리스트에 따라 데이터들을 다시한번 재배열 할수 있어요!
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata
[미션 1] 가장 적절한 고객 관리 타이밍은?_ 분석 및 시각화
import pandas as pd
sparta_data = pd.read_table('/content/access_detail.csv',sep=',')
sparta_data.head()
print(type)
#파이썬의 type()함수를 쓰면, 데이터의 종류를 확인 할수 있어요 :)
print(type(sparta_data['access_date'][1]))
#sparta_date 정보에서 access_date 열에서 데이터 첫번째 부분만 확인 하면 되겠죠?
# 날짜 포맷으로 변경
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
#[날짜 컬럼].dt.day_name 으로 해당 날짜의 요일을 가져 올수 있어요!
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
sparta_data.tail(5)
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
#week의 리스트에 따라 데이터들을 다시한번 재배열 할수 있어요!
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata
import matplotlib.pyplot as plt
import numpy as np
#그래프 사이즈
plt.figure(figsize=(10,5))
plt.rc('font', family='NanumBarunGothic')
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
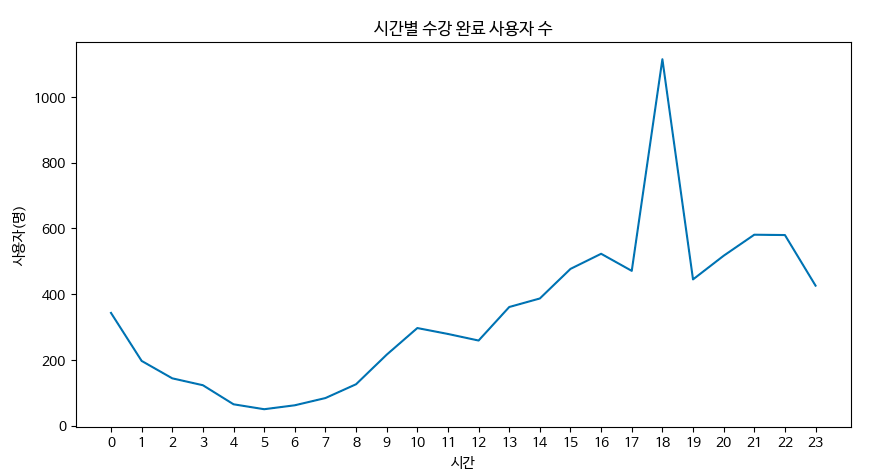
plt.plot(hourdata.index, hourdata)
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24))
#그래프 출력
plt.show()*한글깨짐 방지용
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
[미션 2] 제품 수요가 많은 지역을 찾아라! _ 라인 그래프 그리기
import pandas as pd
sparta_data = pd.read_table('/content/access_detail.csv',sep=',')
sparta_data.head()
print(type)
#파이썬의 type()함수를 쓰면, 데이터의 종류를 확인 할수 있어요 :)
print(type(sparta_data['access_date'][1]))
#sparta_date 정보에서 access_date 열에서 데이터 첫번째 부분만 확인 하면 되겠죠?
# 날짜 포맷으로 변경
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
#[날짜 컬럼].dt.day_name 으로 해당 날짜의 요일을 가져 올수 있어요!
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
sparta_data.tail(5)
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
#week의 리스트에 따라 데이터들을 다시한번 재배열 할수 있어요!
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata
import matplotlib.pyplot as plt
import numpy as np
#그래프 사이즈
plt.figure(figsize=(10,5))
plt.rc('font', family='NanumBarunGothic')
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(hourdata.index, hourdata)
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24))
#그래프 출력
plt.show()
#피벗테이블 만들기
#values : 열에 들어 가는 부분
#index : 행에 들어가는 부분
#aggfunc : 데이터 축약시 사용할 함수
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id',
index=['access_date_time_weekday'],
columns=['access_date_time_hour'],
aggfunc="count").agg(weeks)
sparta_data_pivot_table
#그래프 사이즈 변경
plt.figure(figsize=(14,5))
#pcolor를 이용하여 heatmap 그리기
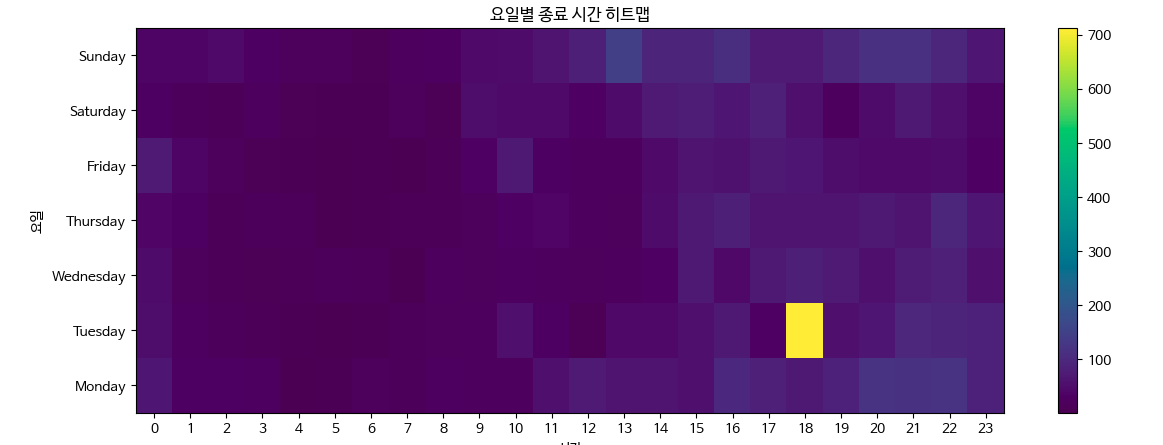
plt.pcolor(sparta_data_pivot_table)
#히트맵에서의 x축
plt.xticks(np.arange(0.5, len(sparta_data_pivot_table.columns), 1), sparta_data_pivot_table.columns)
#히트맵에서의 y축
plt.yticks(np.arange(0.5, len(sparta_data_pivot_table.index), 1), sparta_data_pivot_table.index)
#그래프 명
plt.title('요일별 종료 시간 히트맵')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('요일')
#plt.colorbar() 명령어를 추가하면 그래프 옆에 숫자별 색상값을 나타내는 컬러바를 보여 줍니다
plt.colorbar()
plt.show()
import folium
from folium.plugins import MarkerCluster
sparta_data = pd.read_table('/content/students_area_detail.csv',sep=',')
area_info= sparta_data[['area','latitude','longitude']]
area_info= area_info.drop_duplicates(['area'])
area_info=area_info.sort_values(by=["area"] , ascending=True)
area_info=area_info.reset_index()
area_info
number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
number_of_students
result = pd.merge(area_info, number_of_students, on="area")
result
#sparta_data.head()
m = folium.Map(location=[37.5536067,126.9674308],
zoom_start=11)
m
for n in result.index:
radius = result.loc[n,'user_id']
#loc[n,"열 이름"] => loc[]를 활용하여 n번째의 열을 조회 할수 있습니다!
#즉, n번째의 user의 수를 가져 올수 있는 것이죠!
folium.CircleMarker([result['latitude'][n],result['longitude'][n]],
radius = radius/50, fill=True).add_to(m)
#.add_to(m)를 활용하여, 지정해 두었던 우리나라의 지도를 가져올 수 있습니다!
m
#Pandas 사용 선언하기
import pandas as pd
#데이터 불러오기
sparta_data = pd.read_table('enrolleds_detail.csv',sep=',')
#데이터 확인하기
sparta_data.tail(5)
#시간데이터 전처리 해주기
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['done_date_time'] = pd.to_datetime(sparta_data['done_date'], format=format)
sparta_data.tail(5)
#요일 추가하기
sparta_data['done_date_time_weekday'] = sparta_data['done_date_time'].dt.day_name()
sparta_data.tail(5)
#요일 별 수강완료 수강생 수 전처리 하기
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('done_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
weekdata
#matplotlib 사용 선언하기
import matplotlib.pyplot as plt
#요일 별 수강완료 수강생 수 라인 그래프 그리기
#그래프 사이즈
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()LIST
'Spring & Backend' 카테고리의 다른 글
| [왕초보] 마케터, 기획자를 위한 실전 데이터 분석 5주차[파이썬,python] -스파르타코딩클럽 (0) | 2023.04.11 |
|---|---|
| [왕초보] 마케터, 기획자를 위한 실전 데이터 분석 4주차[파이썬,python] -스파르타코딩클럽 (0) | 2023.04.11 |
| [왕초보] 마케터, 기획자를 위한 실전 데이터 분석 2주차[파이썬,python] -스파르타코딩클럽 (0) | 2023.04.11 |
| [왕초보] 마케터, 기획자를 위한 실전 데이터 분석 1주차[파이썬,python] (0) | 2023.04.11 |
| 금융인을 위한 파이썬 업무자동화 5주차 (0) | 2023.03.29 |