김영한님의 자바ORM 표준 JPA 프로그래밍책으로 공부를 한다. 책으로 공부하는 것도 좋은듯하다. 스프링데이터 예제 프로젝트로 배우는 전자정부 표준데이터베이스 프레임워크~!

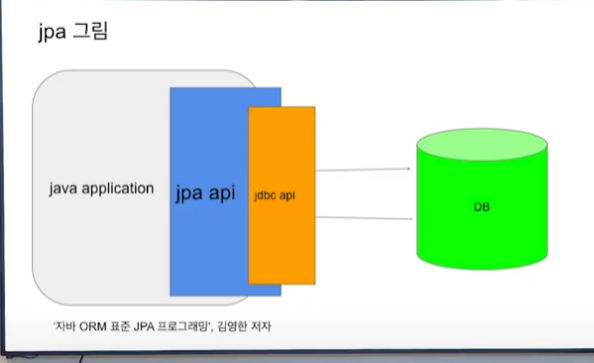
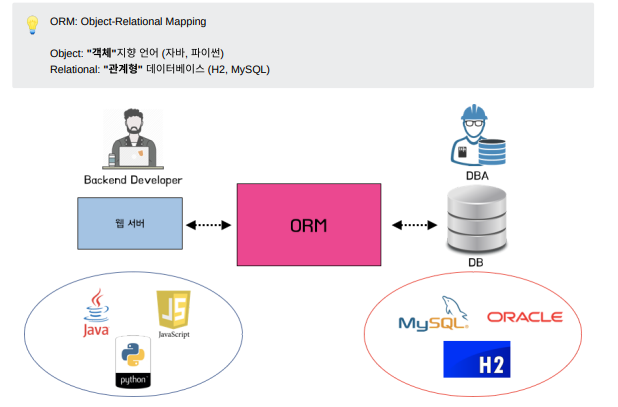
jpa는 CRUD를 생성해주므로 생산적이다. 객체 설계중심으로 db와 연동가능하다. jpa는 상속,연관관계,객첵그래프탐색, 패러다임의 불일치 문제를 해결해준다. 객체지향을 통한 성능최적화를 할 수 있으나 잘 못 사용하면 n+1문제가 나타난다. JPA는 통계쿼리 같이 복잡한 쿼리보다는 실시간 처리용 쿼리에 더 최적화 되어 있다.
김영한님 강의도 있지만... 책으로 하는게 편하다.
https://www.youtube.com/watch?v=ZgtvcyH58ys
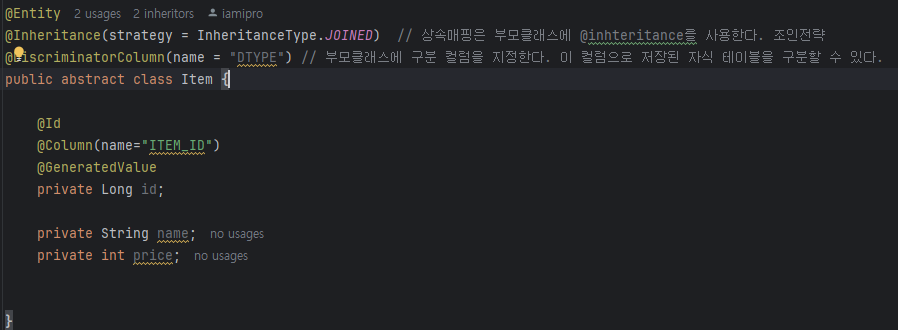
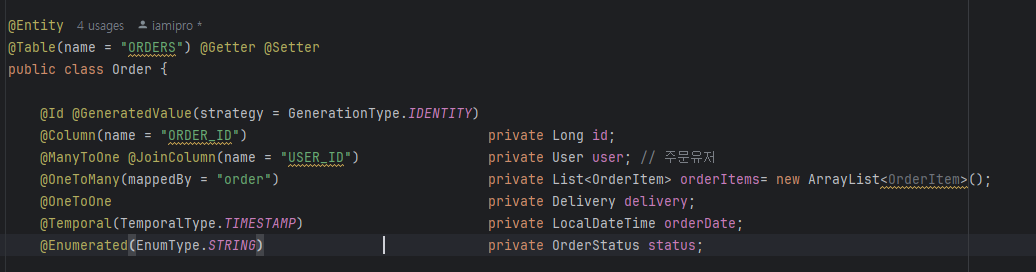
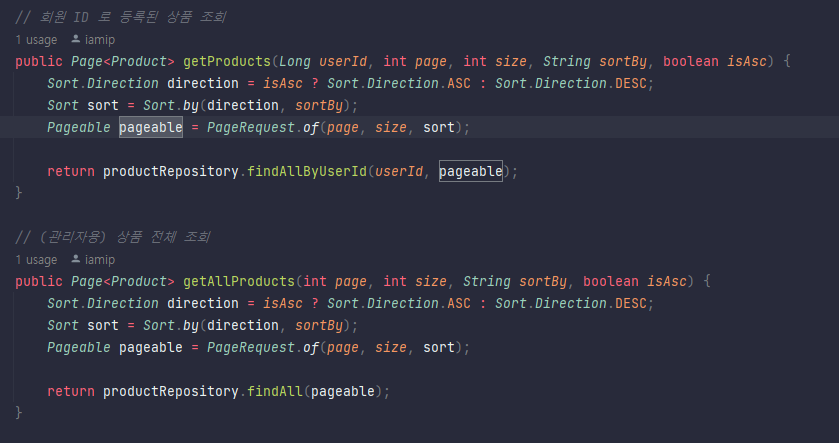
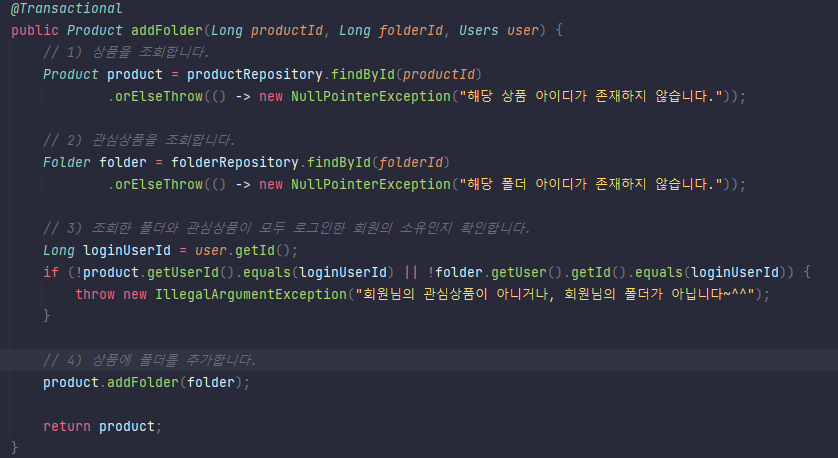
jpql은 엔터티 객체를 대상으로 쿼리한다.(entity 클래스와 필드) jpql 은 table을 모르고 영속성 콘텍스트를 쓴다. 영속성 콘텍스트는 엔터티를 영구저장하는 환경이다. 영속성콘텍스트가 엔터티를 관리하면 1차캐시, 동일성보장,변경감지, 지연로딩, 트랜잭션을 지원하는 쓰기지연 등의 장점이 있다.
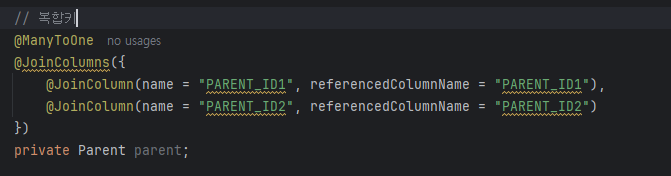
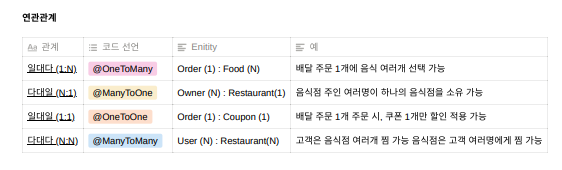
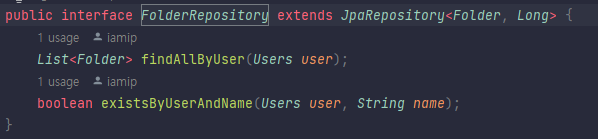
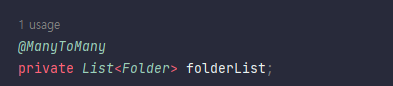
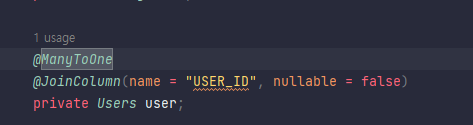
객체는 FK가 아니라 참조주소로 연관관계를 맺고 이는 연관관계 매핑의 핵심이다. 왜래키가 있는곳이 보통 연관관계의 주인이다.
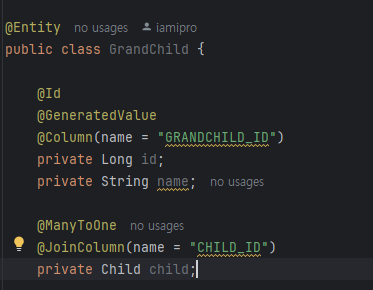
즉시로딩과 지연로딩은 이 양방향엔터티에서 연관된 엔터티를 즉시 조회하는 것이 eager(즉시로딩)이고 사용할 때 로딩 하는 것이 지연로딩(lazy) 이다.
LIST
'Developer > Spring & Backend' 카테고리의 다른 글
| 스프링부트 버전 1.x 대 연구 (0) | 2024.12.04 |
|---|---|
| 스프링을 적용한다는건... (0) | 2024.12.02 |
| JPA 간단정리 2 (0) | 2024.09.16 |
| JPA 간단 정리 1 (0) | 2024.09.12 |
| 백엔드 TDD 비디오가게편 (0) | 2024.09.03 |